> For the complete documentation index, see [llms.txt](https://jheck.gitbook.io/hadoop/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://jheck.gitbook.io/hadoop/apache-spark.md).
# Apache Spark
## Apache Spark
Apache Spark is an open source cluster computing framework for large-scale data processing project that was started in 2009 at the University of California, Berkeley.
Spark was founded as an alternative to using traditional MapReduce on Hadoop, which was deemed to be unsuited for interactive queries or real-time, low-latency applications. A major disadvantage of Hadoop’s MapReduce implementation was its persistence of intermediate data to disk between the Map and Reduce processing phases.
Spark is closely integrated with Hadoop: it can run on YARN and works with Hadoop file formats and storage backends like HDFS.
Spark has more than 400 individual contributors and committers from companies such as Facebook, Yahoo!, Intel, Netflix, Databricks, and others.
Spark maximizes the use of memory across multiple machines, improving overall performance by orders of magnitude.
Spark’s reuse of these in-memory structures makes it well-suited to iterative, machine learning operations, as well as interactive queries.
### Spark Architecture
A Spark application contains several components, all of which exist whether Spark is running on a single machine or across a cluster of hundreds or thousands of nodes.
The components of a Spark application are:
* The Driver Program and the SparkContext Object.
* The Cluster Manager.
* The Executor(s), which run on slave nodes or workers.
####
#### Driver Program
The life of a Spark application starts and finishes with the Driver Program or Spark driver. The Spark driver is the process clients use to submit applications in Spark.
The driver is also responsible for planning and coordinating the execution of the Spark program and returning status and/or results (data) to the client.
The Spark driver is responsible for creating the **SparkContext** object. The SparkContext is instantiated at the beginning of a Spark application (including the interactive shells) and is used for the entirety of the program.
#### Cluster Manager
To run on a cluster, the SparkContext can connect to several types of cluster managers (Spark’s standalone cluster manager, Mesos or YARN), which allocate resources across applications.
Spark is agnostic to the underlying cluster manager. As long as it can acquire executor processes, and these communicate with each other, it is relatively easy to run it even on a cluster manager that also supports other applications (e.g. Mesos/YARN).
#### Executors
Spark executors are the host processes on which tasks from a Spark DAG are run. Executors reserve CPU and memory resources on slave nodes or workers in a Spark cluster. Executors are dedicated to a specific Spark application and terminated when the application completes. A Spark executor can run hundreds or thousands of tasks within a Spark program.
A worker node or slave node, which hosts the executor process, has a finite or fixed number of executors that can be allocated at any point in time.
Executors store output data from tasks in memory or on disk.
Workers and executors are only aware of the tasks allocated to them, whereas the driver is responsible for understanding the complete set of tasks and their respective dependencies that comprise an application.
#### Spark Architecture overview
#### Data Interfaces
There are several key Data interfaces in Spark:
* RDD (Resilient Distributed Dataset): Apache Spark’s first abstraction and most fundamental data object used in Spark programming.
* DataFrame: Collection of distributed Row types. Provide a flexible interface and are similar in concept to the DataFrames in Python (Pandas) or R.
* Dataset: Apache Spark’s newest distributed collection and can be considered a combination of DataFrames and RDDs. Provides the typed interface that is available in RDDs while providing a lot of the conveniences of DataFrames.
#### Transformations and Actions
There are two types of operations that can be performed with Spark: **transformations** and **actions**.
* In Spark, core data structures are immutable. **Transformations**are operations performed against data interfaces (RDD, DataFrame, Dataset) that result in the creation of new data interfaces.
* In contrast to transformations, which return new objects, **actions**produce output such as data from a data interface return to a driver program, or save the content to a file system (local, HDFS, S3, or other).
#### Lazy Evaluation
Spark uses lazy evaluation (also called lazy execution) in processing Spark programs. **Lazy evaluation** defers processing until an action is called (therefore when output is required). After an action such as count() or saveAsTextFile() is requested, a DAG is created along with logical and physical execution plans. These are then orchestrated and managed across executors by the driver.
This lazy evaluation allows Spark to combine operations where possible, thereby reducing processing stages and minimizing the amount of data transferred between Spark executors, a process called the **shuffle**.
#### Spark Stack
The Spark project contains multiple closely integrated components. The core engine of Spark powers multiple higher-level components specialized for various workloads, such as SQL or machine learning.
These components are designed to interoperate closely, letting users combine them like libraries in a software project.
Spark Core contains the basic functionality of Spark, including components for task scheduling, memory management, fault recovery, interacting with storage systems, and more. Spark Core is also home to the API that defines resilient distributed datasets (RDDs).

#### Databricks
Databricks is a company founded by the creators of Apache Spark, that aims to help clients with cloud-based big data processing using Spark. Databricks grew out of the AMPLab project at University of California, Berkeley that was involved in making Apache Spark.
Databricks develops a web-based platform for working with Spark, that provides automated cluster management and IPython-style notebooks.
##
## Lambda Expressions
The lambda operator or lambda function is a way to create small anonymous functions, i.e. functions without a name. These functions are throw-away functions, i.e. they are just needed where they have been created.
Lambda functions are mainly used in combination with the functions **filter()**, **map()** and **reduce()**(**reduce()** is no more supported in Python 3.x).
The general syntax of a lambda function is quite simple: **lambda \ : \**
The argument list consists of a comma separated list of arguments and the expression is an arithmetic expression using these arguments.
The following example of a lambda function returns the sum of its two arguments:
```
sum = lambda x,y : x + y
sum(3,4)
```
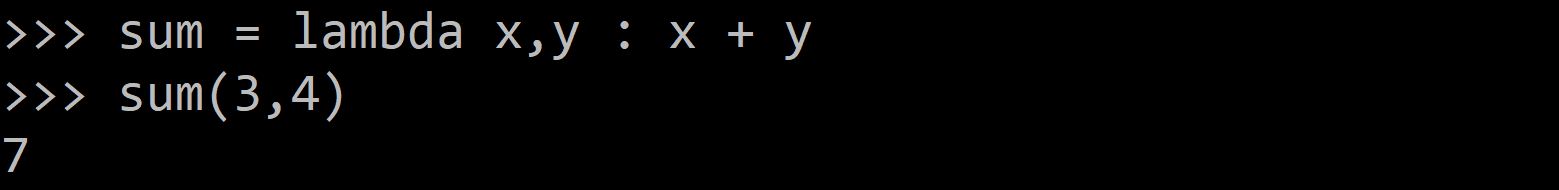
We could have had the same effect by just using the following conventional function definition:
```
def sum(x,y):
return x+y
sum(3,4)
```

### Map() function
The advantage of the lambda operator can be seen when it is used in combination with the **map()** function.
**map()** is a function with two arguments:

The first argument **func** is the name of a function and the second a sequence (e.g. a list) **seq***.* **map()** applies the function **func** to all the elements of the sequence **seq**. It returns a new list with the elements changed by **func**.
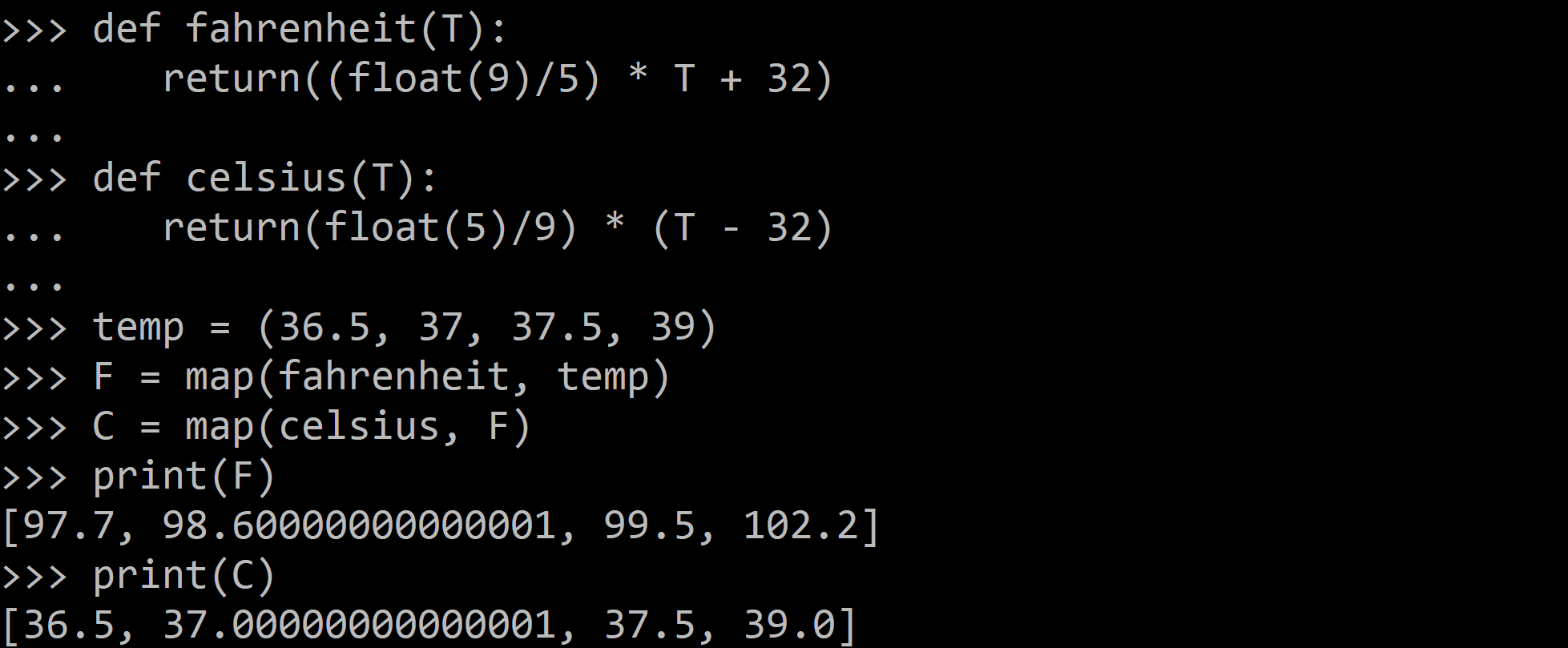
The below example of the **map()** function doesn’t use lambda. By using lambda, we wouldn't have had to define and name the functions ***fahrenheit()** and* **celsius()**.
```
def fahrenheit(T):
return((float(9)/5) * T + 32)
def celsius(T):
return(float(5)/9) * (T - 32)
temp = (36.5, 37, 37.5, 39)
F = map(fahrenheit, temp)
C = map(celsius, F)
```
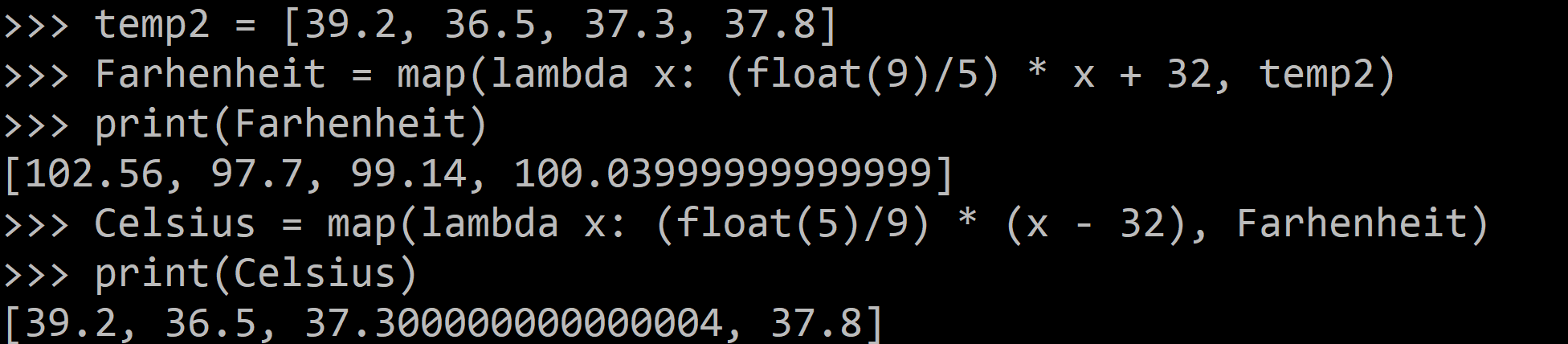
The below example of the map() function use lambda:
```
temp2 = [39.2, 36.5, 37.3, 37.8]
Farhenheit = map(lambda x: (float(9)/5) * x + 32, temp2)
print(Farhenheit)
Celsius = map(lambda x: (float(5)/9) * (x - 32), Farhenheit)
print(Celsius)
```
**map()** can be applied to more than one list but the lists have to have the same length.
**map()** will apply its lambda function to the elements of the argument lists, i.e. it first applies to the elements with the 0th index, then to the elements with the 1st index until the n-th index is reached.
```
a = [1,2,3,4]
b = [17,12,11,10]
c = [-1,-4,5,9]
map(lambda x,y: x+y, a,b)
map(lambda x,y,z: x+y+z, a,b,c)
map(lambda x,y,z: x+y-z, a,b,c)
```

### Reduce() function
The function **reduce** (func, seq) continually applies the function **func()** to the sequence seq. It returns a single value.
If seq= \[ s1, s2, s3, ... , sn ], calling ***reduce**(func,seq)* works like this:
* At first the first two elements of seq will be applied to *func*, i.e. *func(s1,s2)*. The list on which ***reduce()*** works looks now like this: \[func(s1, s2), s3, ... ,sn]
* In the next step **func** will be applied on the previous result and the third element of the list, i.e. func(func(s1, s2),s3). The list looks like this now: \[func(func(s1, s2),s3), ... ,sn]
* Continue like this until just one element is left and return this element as the result of ***reduce()***
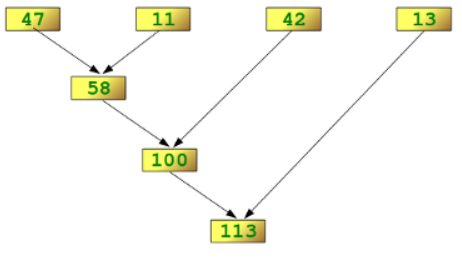
We illustrate this process in the following example:
```
reduce(lambda x,y: x+y, [47,11,42,13])
```

The following diagram shows the intermediate steps of the calculation:
### Exercise Lambda functions
Imagine an accounting routine used in a book shop. It works on a list with sublists, which look like this:
| Order Number | Book Title and Author | Quantity | Price per Item |
| ------------ | ---------------------------------- | -------- | -------------- |
| 34587 | Learning Python, Mark Lutz | 4 | 40.95 |
| 98762 | Programming Python, Mark Lutz | 5 | 56.80 |
| 77226 | Head First Python, Paul Barry | 3 | 32.95 |
| 88112 | Einführung in Python3, Bernd Klein | 3 | 24.99 |
1. In the Python shell, write a Python program that computes the sum of all products of the price per items and the quantity (price per item **x** quantity). To enter the Python shell, open the terminal and type ***python***. Use map and reduce function to do so.\
You can write the list with sublists like the following in the Python shell:
```
orders = [ ["34587", "Learning Python, Mark Lutz", 4, 40.95],
["98762", "Programming Python, Mark Lutz", 5, 56.80],
["77226", "Head First Python, Paul Barry", 3, 32.95],
["88112", "Einfuhrung in Python3, Bernd Klein", 3, 24.99]]
```
The result should be: 624.62
Hints:\
• The input of a ***reduce()*** can be the output of a ***map()***, but this is not mandatory.
2. Write a Python program, which returns a list with 2-tuples. Each tuple consists of the order number and the product of the price per items and the quantity. The product should be increased by $10 if the value of the order is less than $100.00. Write a Python program using lambda and map.
The output of your program should look like this:
```
[('34587', 163.8), ('98762', 284.0), ('77226', 108.85000000000001), ('88112', 84.97)]
```
Hints:
• You can write an IF … ELSE condition in a lambda function.\
• The input of a ***map()*** can be the output of another ***map()***.
## Create a Databricks CE account
Databricks is a managed platform for running Apache Spark providing automated cluster management and IPython-style notebooks.
We can try Databricks for no cost using the Community Edition. To create an account for Databricks CE, follow the below steps:
1. Open Chrome or Firefox.
2. Navigate to
3. Fill in the form 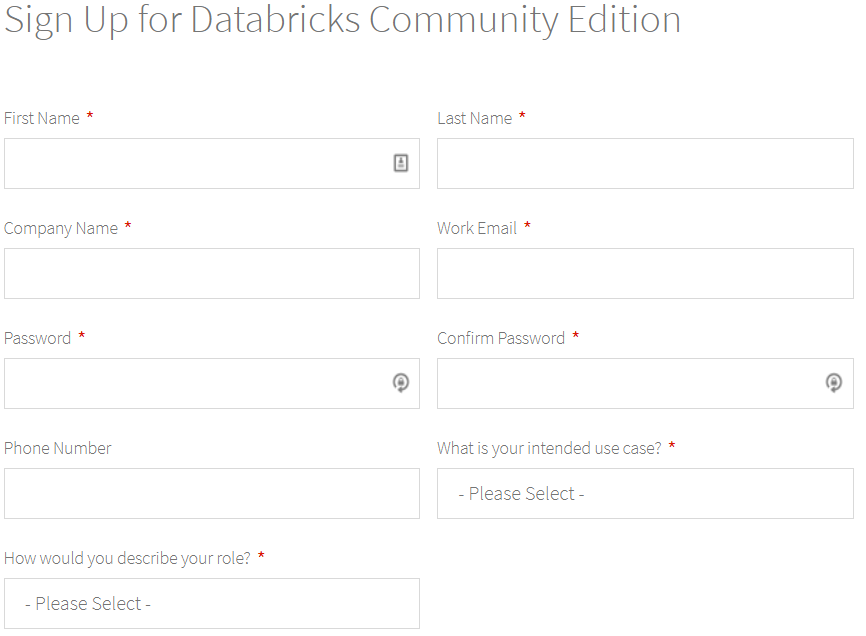
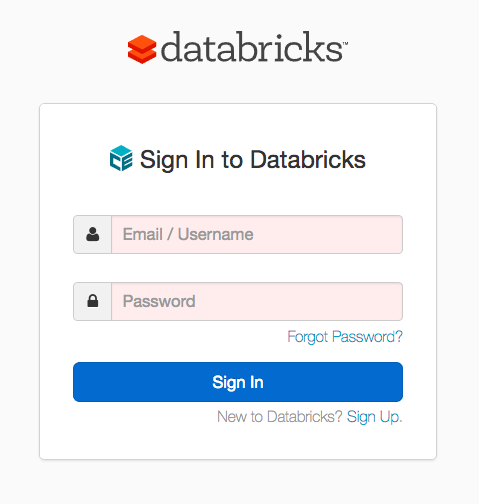
4. Sign in with your email address and password.
#### Explore Databricks
The following items define the fundamental tools that Databricks provides to the end user:
* **Workspaces**: allow you to organize all the work you are doing on Databricks, like a folder structure in your computer. Used to store **Notebooks** and **Libraries**.
* **Notebooks**: set of any number of cells that allow you to execute commands.
* **Libraries**: packages or modules that provide additional functionality that you need to solve your business problems.
* **Tables**: structured data used for analysis.
* **Clusters**: groups of computers that you treat as a single computer. Clusters allow you to execute code from **Notebooks** or **Libraries** on a set of data.
We will explore first explore **Clusters** and **Notebooks**.
#### Create a Spark cluster
Databricks notebooks are backed by clusters, or networked computers that work together to process your data.
To create a Spark cluster, follow the below steps:
1. In the left sidebar, click **Clusters** 
2. Click **Create Cluster** 
3. Name your cluster
4. Select the cluster type. It is recommended to use the latest runtime (**3.3**, **3.4**, etc.) and Scala **2.11**
5. Click the **Create Cluster** button
###
#### Create a new Notebook
Create a new notebook in your home folder:
1. In the sidebar, select the **Home** 
2. Right-click your home folder
3. Select **Create**
4. Select **Notebook**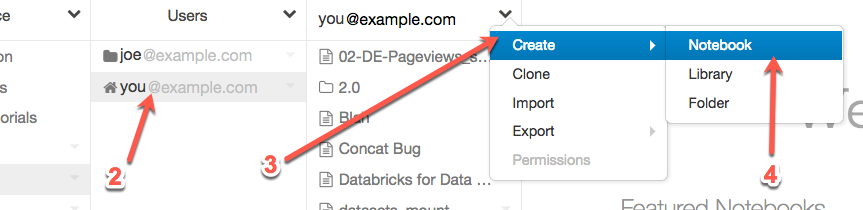
5. Name your notebook
6. Set the language to **Python**
7. Select the cluster to attach this Notebook (NOTE: If a cluster is not currently running, this option will not exist)
8. Click **Create**. Your notebook is created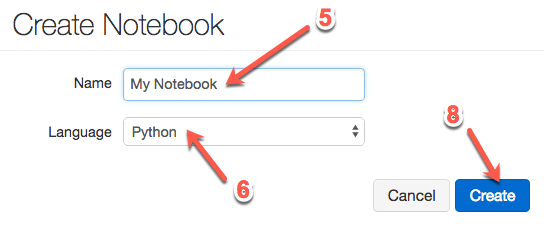
#### Run a notebook cell
Now you have a notebook, you can use it to run code.
1. In the first cell of your notebook, type:`1+1`
2. Run the cell by clicking the run icon and selecting **Run Cell** or simply by typing **Ctrl-Enter**.
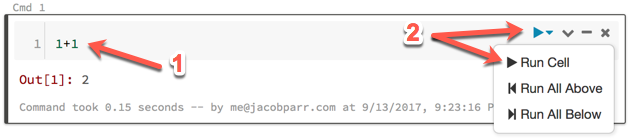
If your notebook was not previously attached to a cluster you might receive the following prompt:
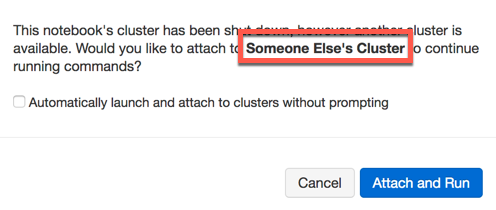
If you click **Attach and Run**, first make sure you attach to the correct cluster.
If your notebook is detached, you can attach it to another cluster:
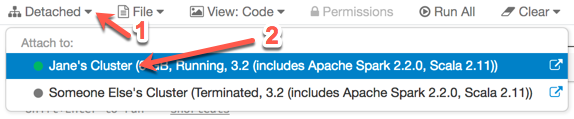
###
#### Import a Notebook
Import the lab files into your Databricks Workspace:
1. In the left sidebar, click **Home**. 
2. Right-click your home folder, then click **Import**.
3. In the popup, click **URL**. 
4. Paste the following URL into the text box:
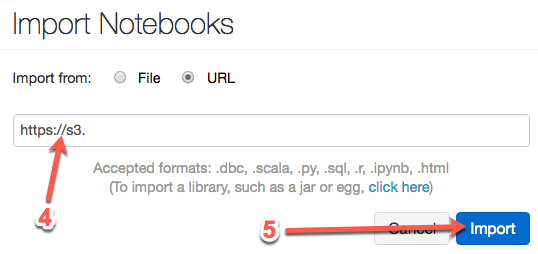
5. Click the **Import** button. The import process may take a couple of minutes to complete.
#### Notebook usage
A notebook is comprised of a linear sequence of cells. Python code cells allow you to execute arbitrary Python commands just like in any Python shell. Place your cursor inside the cell below, and press "Shift" + "Enter" to execute the code and advance to the next cell. You can also press "Ctrl" + "Enter" to execute the code and remain in the cell.+
```
#This code can be run in a Python cell.
print('The sum of 1 and 1 is {0}').format(1+1)
# Another example with a variable (x) declaration and an if statement:
x = 42
if x > 40:
print('The sum of 1 and 2 is {0}').format(2+2)
```
As you work through a notebook it is important that you run all of the code cells. The notebook is stateful, which means that variables and their values are retained until the notebook is detached (in Databricks) or the kernel is restarted (in IPython notebooks). If you do not run all of the code cells as you proceed through the notebook, your variables will not be properly initialized and later code might fail. You will also need to rerun any cells that you have modified in order for the changes to be available to other cells.
```
# This cell relies on x being defined already.
# If we didn't run the cell above this code would fail.
print x * 2
```
### Add a table in Databricks
In Databricks, you can easily create a table from a data file (e.g. csv).
Go to the Data section, click on the default database and then click on the + (plus) sign at the top to create a new table.

For the Data source, select "Upload file" and click on "Drop file or click here to upload". Browse to the file you want to upload.

Once the file has been uploaded, click on "Create Table with UI".

Select a running Cluster and click on "Preview Table".
## Demo Spark
### SparkContext
In order to use Spark and its API we will need to use a ***SparkContext***. When running Spark, you start a new Spark application by creating a SparkContext ().
When using Databricks, the **SparkContext** is created for you automatically as **sc**.
```
sc
```
Historically, Apache Spark has had two core contexts that are available to the user. The **sparkContext** and the **SQLContext** made available as **sqlContext**, these contexts make a variety of functions and information available to the user. The **sqlContext** makes a lot of DataFrame functionality available while the **sparkContext** focuses more on the Apache Spark engine itself.
```
print(sqlContext)
print(sc)
```
In Apache Spark 2.X, there is a new context - the ***SparkSession***** (**).
We can access it via the **spark** variable. As Dataset and Dataframe API are becoming new standard, **SparkSession** is the new entry point for them.
```
# If you're on 2.X the spark session is made available with the variable below
spark
```
**sparkContext** is still used as the main entry point for RDD API and is available under **sc** or **spark.sparkContext**.
```
print(spark.sparkContext)
print(sc)
```
### Transformations and Actions
Spark allows two distinct kinds of operations by the user. There are **transformations** and there are **actions**.
#### Transformations
Transformations are operations that will not be completed at the time you write and execute the code in a cell - they will only get executed once you have called an action. An example of a transformation might be to convert an integer into a float or to filter a set of values.
#### Actions
Actions are commands that are computed by Spark right at the time of their execution. They consist of running all of the previous transformations in order to get back an actual result. An action is composed of one or more jobs which consists of tasks that will be executed by the workers in parallel where possible.
```
# An example of RDD created from a list
numList = [1,2,3,4,5]
firstRDD = sc.parallelize(numList)
# An example of a transformation
# Multiply the values by 2
secondRDD = firstRDD.map(lambda x: x*2)
# An example of an action
secondRDD.collect()
```
It gives a simple way to optimize the entire pipeline of computations as opposed to the individual pieces. This makes it exceptionally fast for certain types of computation because it can perform all relevant computations at once. Technically speaking, Spark **pipelines** this computation which we can see in the image below. This means that certain computations can all be performed at once (like a map and a filter) rather than having to do one operation for all pieces of data and then the following operation.
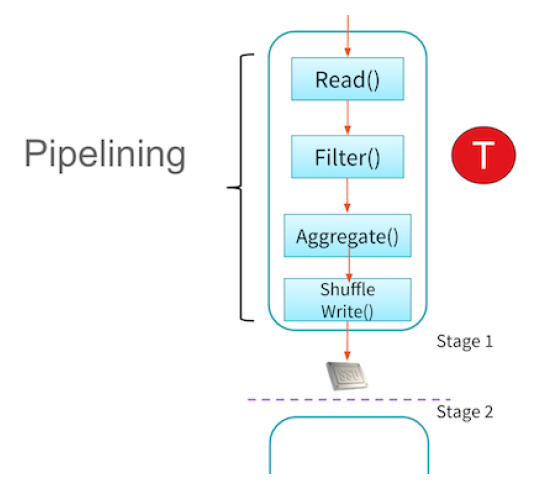
Transformations are **lazy** in order to build up the\
entire flow of data from start to finish required by the user. Any calculation can be recomputed from the very\
source data allowing Apache Spark to handle any failures that occur along the way,\
and successfully handle stragglers. With each transformation Apache Spark creates a plan for how it will\
perform this work.
To get a sense for what this plan consists of, run the following code in a cell (we will explain this code later):
```
wordsList = ['cat', 'elephant', 'rat', 'rat', 'cat']
wordsRDD = sc.parallelize(wordsList)
wordCountsCollected = (wordsRDD
.map(lambda x: (x,1))
.reduceByKey(lambda a,b: a+b)
.collect())
```
Click the little arrow next to where it says (1) Spark Jobs after that cell finishes executing and then click the View link. This brings up the Apache Spark Web UI right inside of your notebook. This can also be accessed from the cluster attach button at the top of this notebook. In the Spark UI, you should see something that includes a diagram similar to this:
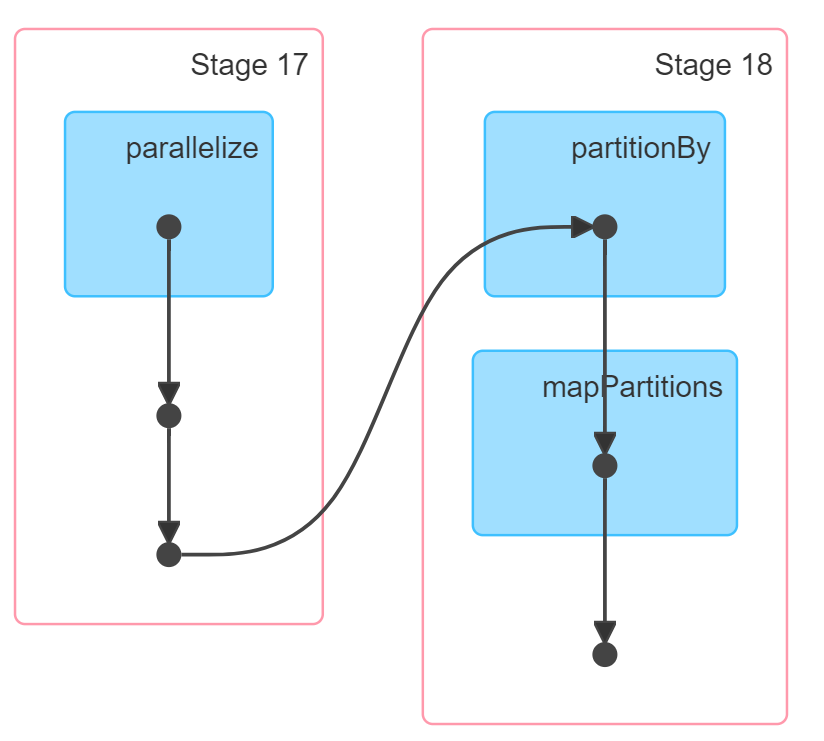This is a Directed Acyclic Graphs (DAG)s of all the computations that have to be performed in order to get to that result. Again, this DAG is generated because transformations are lazy - while generating this series of steps Spark will optimize lots of things along the way and will even generate code to do so.
### Spark example with a Word count application
In this example, we will develop a simple word count application. we will write code that calculates the most common words in the Complete Works of William Shakespeare () retrieved from Project Gutenberg ().
In Databricks, create a new Notebook and follow the steps below.
#### I. Creating a base RDD and pair RDDs
**Create a base RDD**
There are two ways to create RDDs:\_parallelizing\_an existing collection in your driver program, or referencing a dataset in an external storage system, such as a shared filesystem, HDFS, HBase, or any data source offering a Hadoop InputFormat.
Parallelized collections are created by calling ***SparkContext***’s **parallelize** method. The elements of the collection are copied to form a distributed dataset that can be operated on in parallel. One important parameter for parallel collections is the number of **partitions** to cut the dataset into. Spark will run one task for each partition of the cluster. Typically you want 2-4 partitions for each CPU in your cluster. Normally, Spark tries to set the number of partitions automatically based on your cluster. However, you can also set it manually by passing it as a second parameter.
We will start by generating a base RDD by using a Python list and the **sc.parallelize** method. Then we'll print out the type of the base RDD.
Enter the following code in a cell:
```
wordsList = ['cat', 'elephant', 'rat', 'rat', 'cat']
wordsRDD = sc.parallelize(wordsList, 4)
# Print out the type of wordsRDD
print type(wordsRDD)
wordsRDD.collect()
```
**Pluralize and test**
Let's use a \_**map()** \_transformation with a lambda function to add the letter 's' to each string in the base RDD we just created:
```
pluralLambdaRDD = wordsRDD.map(lambda x: x + 's')
print(pluralLambdaRDD.collect())
```
Now let's use **map()** and a **lambda** function to return the number of characters in each word. We will **collect** this result directly into a variable.
```
pluralLengths = (pluralRDD
.map(lambda x: len(x))
.collect())
print(pluralLengths)
```
**Pair RDDs**
The next step in writing our word counting program is to create a new type of RDD, called a pair RDD. A pair RDD is an RDD where each element is a pair tuple **(k, v)** where **k** is the key and **v** is the value. In this example, we will create a pair consisting of **('\', 1)** for each word element in the RDD. We can create the pair RDD using the **map()** transformation with a **lambda()** function to create a new RDD.
```
print(wordsRDD.collect())
wordPairs = wordsRDD.map(lambda x: (x,1))
print(wordPairs.collect())
```
####
#### II. Counting with pair RDDs
Now, let's count the number of times a particular word appears in the RDD. There are multiple ways to perform the counting, but some are much less efficient than others. A naive approach would be to **collect()** all of the elements and count them in the driver program. While this approach could work for small datasets, we want an approach that will work for any size dataset including terabyte- or petabyte-sized datasets. In addition, performing all of the work in the driver program is slower than performing it in parallel in the workers. For these reasons, we will use data parallel operations.
**Use groupByKey() approach**
An approach you might first consider (we'll see shortly that there are better ways) is based on using the ***groupByKey()***\
() transformation. As the name implies, the **groupByKey()** transformation groups all the elements of the RDD with the same key into a single list in one of the partitions.
There are two problems with using ***groupByKey()***:
* The operation requires a lot of data movement to move all the values into the appropriate partitions.
* The lists can be very large. Consider a word count of English Wikipedia: the lists for common words (e.g., the, a, etc.) would be huge and could exhaust the available memory in a worker.
Use **groupByKey()** to generate a pair RDD of type ('word', iterator) .
```
print(wordPairs.collect())
wordsGrouped = wordPairs.groupByKey().mapValues(lambda x: list(x))
#wordsGrouped = wordPairs.groupByKey().map(lambda (x,y): (x,list(y)))
for key, value in wordsGrouped.collect():
print('{0}: {1}'.format(key, value))
```
Using the groupByKey() transformation creates an RDD containing 3 elements, each of which is a pair of a word and a Python iterator.
**mapValues** pass each value in the key-value pair RDD through a map function without changing the keys. In this case the map changes the iterator to a list of values. **mapValues** is only applicable for PairRDDs.
Now sum the iterator using a map() transformation. The result should be a pair RDD consisting of (word, count) pairs.
```
print(wordsGrouped.collect())
wordCountsGrouped = wordsGrouped.map(lambda (k,v): (k,sum(v)))
#wordCountsGrouped = wordsGrouped.mapValues(lambda v: sum(v))
print(wordCountsGrouped.collect())
```
NOTE:`lambda (k,v):`does not work in Python 3.
**Use reduceByKey approach**
A better approach is to start from the pair RDD and then use the ***reduceByKey()***() transformation to create a new pair RDD. The **reduceByKey()** transformation gathers together pairs that have the same key and applies the function provided to two values at a time, iteratively reducing all of the values to a single value. **reduceByKey()** operates by applying the function first within each partition on a per-key basis and then across the partitions, allowing it to scale efficiently to large datasets.
```
print(wordPairs.collect())
wordCounts = wordPairs.reduceByKey(lambda a,b: a+b)
print(wordCounts.collect())
```
The expert version of the code performs the **map()** to pair RDD, **reduceByKey()** transformation, and **collect** in one statement.
```
print(wordsRDD.collect())
wordCountsCollected = (wordsRDD
.map(lambda x: (x,1))
.reduceByKey(lambda a,b: a+b)
.collect())
print(wordCountsCollected)
```
####
#### III. Apply word count to a file
Let's finish developing our word count application. We will have to build the wordCount function, deal with real world problems like capitalization and punctuation, load in our data source, and compute the word count on the new data.
**wordcount function**
First, let's define a function for word counting. We will reuse the techniques that we saw earlier. This function should take in an RDD that is a list of words like wordsRDD and return a pair RDD that has all of the words and their associated counts.
```
def wordCount(wordListRDD):
"""Creates a pair RDD with word counts from an RDD of words.
Args:
wordListRDD (RDD of str): An RDD consisting of words.
Returns:
RDD of (str, int): An RDD consisting of (word, count) tuples.
"""
wordListCount = (wordListRDD.map(lambda x: (x,1))
.reduceByKey(lambda a,b: a+b))
return wordListCount
```
**Capitalization and punctuation**
Real world files are more complicated than the data we have been using so far.
Some of the issues we have to address are:
* Words should be counted independent of their capitialization (e.g., Spark and spark should be counted as the same word).
* All punctuation should be removed.
* Any leading or trailing spaces on a line should be removed.
We will now define the function **removePunctuation** that converts all text to lower case, removes any punctuation, and removes leading and trailing spaces. We will use the Python **re** () module to remove any text that is not a letter, number, or space.
More on regular expressions here:
```
import re
def removePunctuation(text):
"""Removes punctuation, changes to lower case, and strips leading and trailing spaces.
Note:
Only spaces, letters, and numbers should be retained. Other characters should should be eliminated
(e.g. it's becomes its).
Leading and trailing spaces should be removed after punctuation is removed.
Args:
text (str): A string.
Returns:
str: The cleaned up string.
"""
return re.sub(r'[^A-Za-z0-9 ]', '', text).lower().strip()
print removePunctuation('Hi, you!')
print removePunctuation(' No under_score!')
print removePunctuation(' * Remove punctuation then spaces * ')
```
**Load a text file**
We will use the Complete Works of William Shakespeare () from Project Gutenberg ().
To convert a text file into an RDD, we use the **SparkContext.textFile()** method. We also apply the recently defined **removePunctuation()** function using a **map()** transformation to strip out the punctuation and change all text to lower case. Since the file is large we use take(15) , so that we only print 15 lines.
NOTE: the file has already been uploaded in Databricks FS for us.
```
import os.path
baseDir = os.path.join('databricks-datasets')
inputPath = os.path.join('cs100', 'lab1', 'data-001', 'shakespeare.txt')
fileName = os.path.join(baseDir, inputPath)
shakespeareRDD = (sc.textFile(fileName, 8).map(removePunctuation))
print '\n'
.join(shakespeareRDD
.zipWithIndex() # to (line, lineNum)
.map(lambda (l, num): '{0}: {1}'.format(num, l)) # to 'lineNum: line'
.take(15))
```
**Words from lines**
Before we can use the **wordcount()** function, we have to address two issues with the format of the RDD:
* The first issue is that that we need to split each line by its spaces.
* The second issue is we need to filter out empty lines.
To solve the first issue, we will apply, for each element of the RDD, Python's string ***split()***() function.
We also would like the newly created RDD to consist of the elements outputted by the function. Simply applying a **map()** transformation would yield a new RDD made up of iterators. Each iterator could have zero or more elements. Instead, we often want an RDD consisting of the values contained in those iterators. The solution is to use a **flatMap()**() transformation, **flatMap()** is similar to **map()**, except that with **flatMap()** each input item can be mapped to zero or more output elements.
Look at the difference between map() and flatMap() by running this code:
```
# Let's create a new base RDD to work from
wordsList = ['cat', 'elephant', 'rat', 'rat', 'cat']
wordsRDD = sc.parallelize(wordsList, 4)
# Use map
singularAndPluralWordsRDDMap = wordsRDD.map(lambda x: (x, x + 's'))
# Use flatMap
singularAndPluralWordsRDD = wordsRDD.flatMap(lambda x: (x, x + 's'))
# View the results
print singularAndPluralWordsRDDMap.collect()
print singularAndPluralWordsRDD.collect()
# View the number of elements in the RDD
print singularAndPluralWordsRDDMap.count()
print singularAndPluralWordsRDD.count()
```
Hence our code for our word count application should be:
```
shakespeareWordsRDD = shakespeareRDD.flatMap(lambda x: x.split(' '))
shakespeareWordCount = shakespeareWordsRDD.count()
print shakespeareWordsRDD.top(5)
print shakespeareWordCount
```
**Remove empty lines**
The next step is to filter out the empty elements using the **filter()** function:
```
shakeWordsRDD = shakespeareWordsRDD.filter(lambda x: x <> '')
shakeWordCount = shakeWordsRDD.count()
print shakeWordCount
```
**Count the words**
We now have an RDD that is only words. Next, let's apply the **wordCount()** function to produce a list of word counts. We can view the top 15 words by using the **takeOrdered()** action; however, since the elements of the RDD are pairs, we need a custom sort function that sorts using the value part of the pair.
```
top15WordsAndCounts = wordCount(shakeWordsRDD).takeOrdered(15, lambda (w,c): - c)
print '\n'.join(map(lambda (w, c): '{0}: {1}'.format(w, c), top15Word
```
## Exercise Spark with RDD
In this exercise, using the movielens datasets, let's find all the movies with the lowest average rating, meaning the bad movies.
#### Upload files in DBFS
Let's start by uploading our datasets in DBFS, the Databricks filesytem.
Go to the Data section, click on the default database and then click on the + (plus) sign at the top to create a new table.

For the Data source, select "Upload file". Create a directory **movielens**in **/FileStore/tables/** by typing "movielens" in the **Upload to DBFS**field:

Click on "Drop file or click here to upload". Browse to the **u.data** file.

Do NOT create a table. Perform the same steps for the **u.item** file (for the **Upload to DBFS part**, you can click on Select and select the movielens directory).
### Exercise Spark RDD
Once the files have been uploaded, check the path were the file has been saved in DBFS (e.g. "/FileStore/tables/movielens/u.item") and udpdate the code below if needed.
```
#List the path of the u.item and u.data
#display(dbutils.fs.ls("/FileStore/tables"))
display(dbutils.fs.ls("/FileStore/tables/movielens"))
```
Now that our files are available in DBFS, let's create their corresponding RDDs using the textFile() method:
```
# Load u.item data
#rawItem = sc.textFile("")
rawItem = sc.textFile("/FileStore/tables/movielens/u.item")
# Load u.data data
#rawData = sc.textFile("")
rawData = sc.textFile("/FileStore/tables/movielens/u.data")
```
For now, our RDDs are just lines of our initial text files (e.g. check: print(rawData.collect()) ). We will use Python's split() function that we saw earlier to separate each field. We need to provide the split() function with the file delimiter to do so.
Next we need to extract the fields we will use to solve our problem.
* u.data is tab ("\t") delimited and we need to extract movie\_id (index 1) and rating (index 2). Additionally, to compute the average rating per movie, we want a tuple of the form (rating, 1.0) per movie\_id
* u.item is pipe ("|") delimited and we need to extract movie\_id (index 0) and title (index 1).
To summarize, you will need to
1. split the lines
2. extract/map the fields we want to a new RDD (do NOT use flatmap() ).
```
# From rawData, create a new RDD of the form: (movie_id, (rating, 1.0))
movieRatings = rawData.
```
```
# From rawItem, create a new RDD of the form: (movie_id, title)
movieList = rawItem.
```
Next step will be to sum the ratings and count the number of ratings per movie\_id so we will be able to compute the average rating per movie. We saw a function that gathers together pairs that have the same key and applies the function provided to two values at a time. We might want to use such function to sum/count values sharing the same key.
```
# From movieRatings, create a new RDD of the form: (movie_id (sumOfRatings, totalRatings))
ratingTotalsAndCount = movieRatings.
```
Once we have our sum of ratings and our total ratings per movie\_id, we can easily compute the average rating by dividing the sum of ratings by the total number of ratings. Since we want to access elements within a tuple to compute the average rating per movie, we can use the array notation, e.g. x\[n] to access the nth element of a tuple x.
As a concrete example, if we have a RDD of the form **(x,y)** with **x** being the key and **y** being a tuple of the form **(a,b)**, we can access **a** using **y\[0]** and **b** using **y\[1]**.
Hint: We can map only the VALUES from our RDD, but this is not mandatory.
```
# From ratingTotalsAndCount, create a new RDD of the form: (movieID, AverageRating)
averageRatings = ratingTotalsAndCount.
```
We are almost done! We can now sort by average rating using the sortBy() function. Check how this function works in the pyspark API documentation:
```
#Sort by average Rating
sortedMovies = averageRatings.
```
In our sortedMovies RDD, we are missing the title for each movie\_id. This field is in the movieList RDD (form: (movie\_id, title) ).
We can join two RDDs using the join function:
The result RDD will be of the form: **(k, (v1, v2))**, where **(k, v1)** and **(k, v2)** are the two joining RDDs and **k** is the matching key.
```
# Join averageRatings with movieList. The result RDD will be of the form: (movie_id,(averageRating, title))
joinRDD =
```
Finally, let's sort by average rating and keep the movie title and the average rating only.
```
# Keep title and average rating only and sort by average Rating. The result RDD should have the form: (averaRating, title)
results = joinRDD.
results.collect()
```
### Bonus exercise Spark RDD
Our solution for finding the lowest-rated movies is polluted with movies rated by one or two people.
Modify our previous solution to only consider movies with at least ten ratings.
HINTS:
* We saw that RDD's have a function to **filter** records. It takes a function as a parameter, which accepts the entire key/value pair. This function should be an expression that returns True if the row should be kept, or False if it should be discarded.
* If you have an RDD that contains (movie\_id, (sumOfRatings, totalRatings)), a lambda function that takes in "x" would refer to totalRatings as x\[1]\[1]. x\[1] gives us the "value" of (sumOfRatings, totalRatings) and x\[1]\[1] pulls out totalRatings.
Finally, you should be able to specify the table attributes, such as the table and the columns name and the data type of each column.

Click on "Create Table" once you are done. You can now access the table in Databricks using Spark SQL commands.