> For the complete documentation index, see [llms.txt](https://jheck.gitbook.io/hadoop/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://jheck.gitbook.io/hadoop/hive.md).
# Hive
### Introduction to Hive
Apache Hive is a framework for data warehousing on top of Hadoop.
Similarly to Pig, the motivation for Hive was that few analysts were available with Java MapReduce programming skills, without the need to create a brand new language, as it was done with Pig Latin.
The Hive project introduced a new language called HiveQL (or Hive Query Language) that is very similar to SQL.
#### Advantages of Hive
* Hive uses familiar SQL syntax (HiveQL), making it easy to use for most data analyst
* Interactive, like a traditional RDBMS
* Scalable: Hive works on a cluster of machines as opposed to a traditional database on a single host
* Easy OLAP queries: like with Pig, it is way easier than writing the equivalent MapReduce in Java
* Highly extensible (e.g. User defined functions, JDBC/ODBC driver, etc.)
#### Hive vs RDBMS
* High latency – not appropriate for OLTP
* Stores data de-normalized in HDFS
* For UPDATE, INSERT and DELETE in Hive, delta files are periodically merged into the base table files by MapReduce jobs that are run in the background by the metastore.
* No journaling, no rollbacks
* No primary keys, no foreign keys (but Hive supports indexes)
* Incorrectly formatted data (for example, mistyped data or malformed records) are simply represented to the client as NULL
### Schema on Read vs Schema on Write
#### **Schema on write**
* The data is checked against the schema when it is written into the database.
* Query time performance is faster because the database can index columns and perform compression on the data.
#### **Schema on read**
* The data is checked when a query is issued.
* Very fast initial load, since the data does not have to be read, parsed, and serialized to disk in the database’s internal format. The load operation is just a file copy or move.
* More flexible: we can have two schemas for the same underlying data, depending on the analysis to be performed.
* Sometimes the schema is not known at load time, so there are no indexes to apply, because the queries have not been formulated yet.
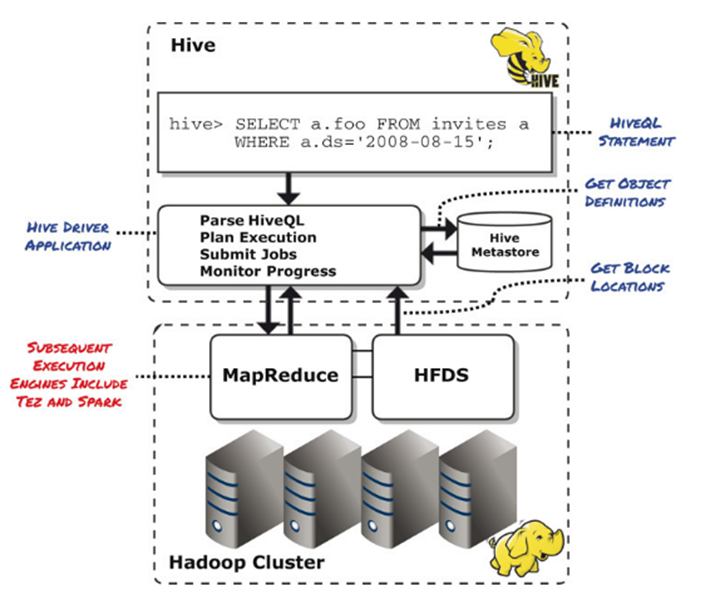
### Hive Objects and the Hive Metastore
Hive implements a tabular abstraction to objects in HDFS: it presents directories and files as tables. Similar as in conventional relational databases, tables have predefined columns with designated datatypes. Data in HDFS can then be accessed via SQL statements. Mapping of tables to their directory or file locations in HDFS and the columns and their definitions are maintained in the Hive metastore.
Hive Metastore is a relational database (!) and is seen as the central repository of Hive metadata.
### Create new table
```
-- Create folder hive/table_creation in HDFS and copy u.data
CREATE TABLE ratings1 (
userID INT,
movieID INT,
rating INT,
time INT)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION '/user/ubuntu/hive/table_creation';
SELECT * FROM ratings1
LIMIT 100;
```
### Import Data into Hive table
We can populate a Hive table using:
* LOAD DATA
* INSERT (OVERWRITE)
* CREATE TABLE … AS SELECT
* From a relational database using Sqoop (this will be covered later)
```
---- 1. LOAD
CREATE TABLE IF NOT EXISTS ratings2 (
userID INT,
movieID INT,
rating INT,
time INT)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
-- Create folder hive/table_load in HDFS and copy u.data
LOAD DATA INPATH '/user/ubuntu/hive/table_load'
INTO TABLE ratings2;
-- Browse to /user/ubuntu/hive/table_load
-- Browse to /user/hive/warehouse/movielens.db/ratings2;
```
```
---- 2. CTAS
CREATE TABLE ratings_ctas
AS
SELECT * FROM ratings1;
-- Browse to /user/hive/warehouse/movielens.db/ratings_ctas
```
```
---- 3. INSERT INTO
INSERT INTO TABLE ratings_ctas
SELECT s.* FROM ratings1 s;
-- Browse to /user/hive/warehouse/movielens.db/ratings_ctas
```
```
---- 4. INSERT OVERWRITE
INSERT OVERWRITE TABLE ratings_ctas
SELECT s.* FROM ratings1 s;
-- Browse to /user/hive/warehouse/movielens.db/ratings_ctas
```
### Managed and External table
* When creating a table in Hive, Hive will, by default, manage the data
* Hive move the data into its warehouse directory if LOCATION is not specified.
* If the table is dropped, the table, its metadata and its data are deleted.
* LOAD performed a move operation, and the DROP performed a delete operation.
* This type of table is called “Managed Table”.
Alternatively, we can create an external table
* Using the EXTERNAL keyword.
* Hive doesn’t move the table to its warehouse directory during LOAD operation.
* DROP TABLE operation does not delete the directory and files, only deletes the metadata.
* Hive doesn’t check whether the external location exists at the time it is defined.
* We control the creation and deletion of the data, not Hive
```
-- Create tables ratings1 and ratings2 if not done yet or skip to drop table
CREATE TABLE ratings1 (
userID INT,
movieID INT,
rating INT,
time INT)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION '/user/ubuntu/hive/table_creation';
CREATE TABLE IF NOT EXISTS ratings2 (
userID INT,
movieID INT,
rating INT,
time INT)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
LOAD DATA INPATH '/user/ubuntu/hive/table_load'
INTO TABLE ratings2;
DROP TABLE ratings1;
--Browse to /user/ubuntu/hive/table_creation;
DROP TABLE ratings2;
--Browse to /user/hive/warehouse/movielens.db/ratings2;
```
```
-- Creating external table without LOCATION
CREATE EXTERNAL TABLE IF NOT EXISTS ratings (
userID INT,
movieID INT,
rating INT,
time INT)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
-- Create folder hive/ext_table in HDFS and copy u.data
LOAD DATA INPATH '/user/ubuntu/hive/ext_table'
OVERWRITE INTO TABLE ratings;
DROP TABLE ratings;
-- Browse to Browse to /user/hive/warehouse/movielens.db/ratings
```
```
-- Creating external table with LOCATION
-- Create folder hive/ext_table in HDFS and copy u.data
CREATE EXTERNAL TABLE IF NOT EXISTS ratings (
userID INT,
movieID INT,
rating INT,
time INT)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LOCATION '/user/ubuntu/hive/ext_table';
DROP TABLE ratings;
-- Browse to Browse to /user/ubuntu/hive/ext_table
```
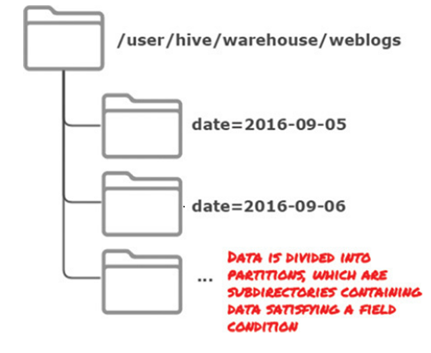
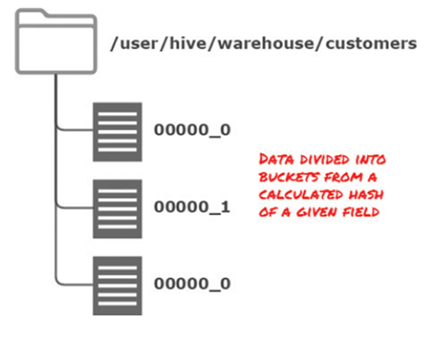
### Partitioning tables and Bucketing
Hive offers two key approaches used to limit or restrict the amount of data that a query needs to read: **Partitioning** and **Bucketing**
* **Partitioning** is used to divide data into subdirectories based upon one or more conditions that typically would be used in WHERE clauses for the table.
* Typically used for coarse-grained date grouping (e.g., a date without the time component, month, or year).
* We can still run queries that span multiple partitions.
* **Bucketing** is used to group items based upon a key hash.
* Tables or partitions may be subdivided further into buckets.
* Bucketing involves calculating a hash code for values inserted into bucketed (or clustered) columns.
* Hash code ranges are then assigned to one or a predefined number of buckets.
Partitioning creates subdirectories for each partition, whereas bucketing creates separate data files for each bucket.
Common Example of Partitioning: logfiles
* Each record includes a timestamp.
* If we partition by date, then records for the same date will be stored in the same partition.
* Queries that are restricted to a particular date or set of dates can run much more efficiently
```
-- Create folder hive/crime_la/crime_data_la and copy crime_data_la.csv
CREATE EXTERNAL TABLE IF NOT EXISTS crime_data_la (
dr_number INT,
reported_dt DATE,
occured_dt DATE,
occured_tm INT,
area_id INT,
district_id INT,
crime_code INT,
victim_age INT,
victim_sex STRING,
victim_descent STRING,
coord_lat FLOAT,
coord_long FLOAT)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
LOCATION '/user/ubuntu/hive/crime_la/crime_data_la';
```
```
CREATE TABLE IF NOT EXISTS crime_la_part (
dr_number INT,
reported_dt DATE,
occured_dt DATE,
occured_tm INT,
area_id INT,
district_id INT,
crime_code INT,
victim_age INT,
victim_sex STRING,
victim_descent STRING,
coord_lat FLOAT,
coord_long FLOAT)
PARTITIONED BY (year_rept STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
;
INSERT OVERWRITE TABLE crime_la_part
PARTITION (year_rept = 2017)
SELECT * FROM crime_data_la c
WHERE YEAR(c.reported_dt) = 2017;
INSERT OVERWRITE TABLE crime_la_part
PARTITION (year_rept = 2016)
SELECT * FROM crime_data_la c
WHERE YEAR(c.reported_dt) = 2016;
SHOW PARTITIONS crime_la_part;
DESCRIBE FORMATTED crime_la_part;
-- Browse to /user/hive/warehouse/movielens.db/crime_la_part/year_rept=2016
-- Browse to /user/hive/warehouse/movielens.db/crime_la_part/year_rept=2017
```
```
ALTER TABLE crime_la_part DROP IF EXISTS PARTITION(year_rept = 2017);
SHOW PARTITIONS crime_la_part;
SELECT * FROM crime_la_part
WHERE YEAR(reported_dt) = 2017;
-- Browse to /user/hive/warehouse/movielens.db/crime_la_part/
ALTER TABLE crime_la_part DROP IF EXISTS PARTITION(year_rept = 2016);
-- Browse to /user/hive/warehouse/movielens.db/crime_la_part/
```
Bucketing is commonly used for two main reasons:
* Enable more efficient queries by imposing extra structure on the table. In particular, a join of two tables that are bucketed on the same columns — which include the join columns — can be efficiently implemented as a map-side join.
* Make sampling more efficient: try out queries on a fraction of your dataset.
### Exercise
Create folder hive/crime\_la/area\_name and copy crime\_data\_area\_name.csv
Create folder hive/crime\_la/code\_name and copy crime\_data\_code\_name.csv
1.Create **external** tables for **area\_name**(area\_code INT, area\_name STRING) and **code\_name** (code INT, code\_name STRING)
1. Create table **crime\_la** with columns
2. dr\_number INT, reported\_dt DATE, occured\_dt DATE, area\_id INT, crime\_code INT, coord\_lat FLOAT, coord\_long FLOAT)
3. Partition by area\_name
4. Insert data from crime\_data\_la and area\_name to crime\_la **where area\_name = 'Hollywood'**
5. Insert data from crime\_data\_la and area\_name to crime\_la **where area\_name= 'Central'**
6. Select data from crime\_la and code\_name **where code\_name = 'CRIMINAL HOMICIDE’ and area\_name = 'Hollywood’**
### Exercise Pig and Hive
1. Using Pig, create a relation combining **crime\_data\_la.csv** and **crime\_data\_area\_name.csv** files.
2. The (final) relation should have variables **dr\_number**, **area\_id**, **area\_name** and **crime\_code**
3. Store the output in a new folder ‘**crime\_area\_name**’
4. Data should be semicolon (;) separated
5. Using Hive, create the new external table crime\_area\_name using the output generated previously.
6. Create table **crime\_la\_final** combining **crime\_area\_name** and **code\_name** (created in previous exercise)
7. Create partitioned table **crime\_la\_final\_part** partitioned on **crime\_code** with columns:
8. dr\_number INT, area\_id INT, area\_name STRING, code\_name STRING
9. From **crime\_la\_final** table, insert data into **crime\_la\_final\_part**for **crime\_code** **110**, **210** and **310**
---
# Agent Instructions
This documentation is published with GitBook. GitBook is the documentation platform designed so that both humans and AI agents can read, navigate, and reason over technical content effectively. Learn more at gitbook.com.
## Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter:
```
GET https://jheck.gitbook.io/hadoop/hive.md?ask=
```
The question should be specific, self-contained, and written in natural language.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.